GPT4Point: A Unified Framework for Point-Language Understanding and Generation
 Overall framework
Overall framework
Abstract
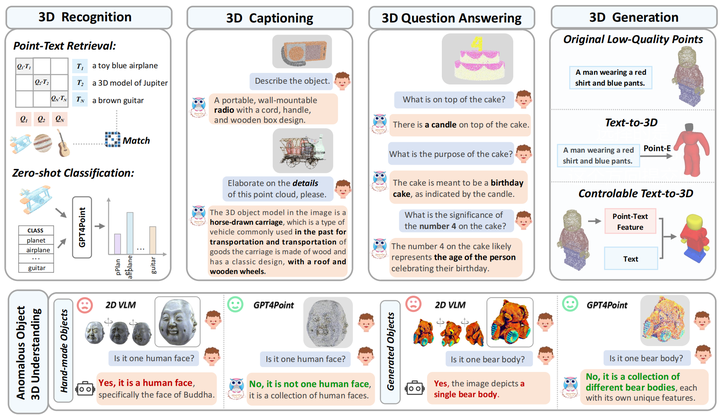
Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.
Tong WU 吴桐
PostDoc @ Stanford
My research interests include 3d vision, long-tailed recognition, and robustness.