 Overall framework
Overall framework
Abstract
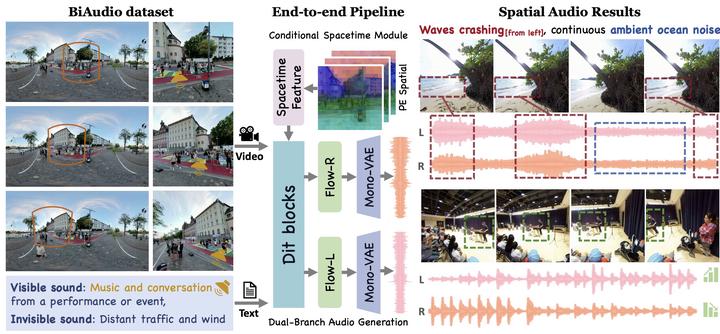
ViSAudio tackles end-to-end binaural spatial audio generation directly from silent video. It introduces the BiAudio dataset and a conditional flow matching architecture with dual audio branches and a conditional spacetime module for spatially consistent audio generation.
Type
Publication
arXiv preprint
Tong WU 吴桐
Assistant Professor @ Fudan
My research interests include 3d vision, long-tailed recognition, and robustness.